
Overview
I was curious about the mechanisms by which AI agents execute Google searches when users request them, and in this article I would like to share my analysis and insights on this topic. When an AI agent (like ChatGPT, LangChain agents, AutoGPT, etc.) “searches Google,” it typically doesn’t directly access google.com and input text. Instead, it employs sophisticated approaches that I will outline in detail in this blog. Please note that this represents my own analysis and personal understanding. I’m still learning and would welcome discussion with experienced practitioners.
Key Topics Covered in This Analysis
- Introduction
- Search Strategies Used by AI Agents
- Query Construction Patterns
- Direct Google UI vs Custom Search API
- End-to-End Agent Workflows
- Free vs Paid Agent Capabilities
- References
Search Strategies Employed by AI Agents
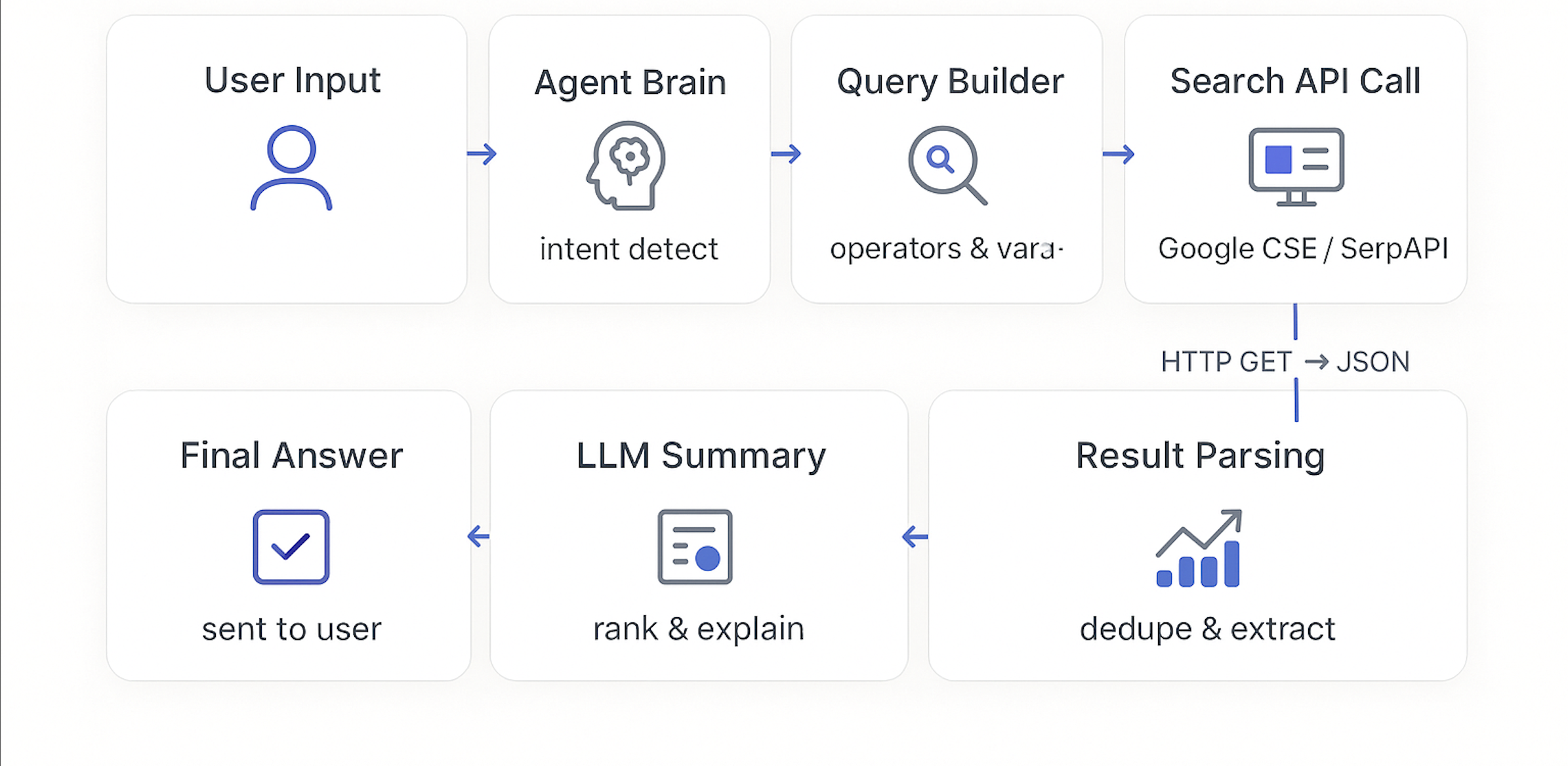
When an AI agent determines that the user query requires Google search capabilities, it implements one of these methodologies:
Custom Search APIs
- Google offers the Custom Search JSON API: https://developers.google.com/custom-search/v1/overview
- The agent sends a structured HTTP request (with the query, filters, number of results, etc.).
- The API responds with JSON containing titles, snippets, and URLs.
Web Scraping with Headless Browser Automation (less common, higher risk)
- Some agents utilize Puppeteer, Playwright, or Selenium to simulate user interactions with Google’s interface and extract results.
- This approach is inherently fragile and frequently violates Google’s Terms of Service.
Third-Party Search API Integration
- Agents commonly integrate with alternative services such as SerpAPI, Bing Web Search API, or DuckDuckGo APIs.
- These services manage the web scraping and legal compliance aspects, returning structured JSON responses.
Query Construction Methodologies
AI agents typically employ sophisticated query construction strategies rather than traditional information retrieval (IR) ranking algorithms:
- Precision Query Construction
- Implement advanced search operators including site:, filetype:, intitle:, and exact phrase matching with quotes.
- Operator specifications:
- site: -> constrains results to specific domains (e.g., site:linkedin.com).
- filetype: -> filters by document types (e.g., filetype:pdf).
- intitle: -> mandates keyword presence in page titles.
- Quotes “…” -> enforces exact phrase matching.
- Operator specifications:
- Example: Instead of a basic query like “Software Engineer Job NYC”, the agent constructs:
bash "Software Engineer" "New York" site:indeed.com
- Implement advanced search operators including site:, filetype:, intitle:, and exact phrase matching with quotes.
- Concise Query Optimization
- Methodology: Distill queries to essential keywords, eliminating operators and extraneous terms.
- Objective: Maximize recall by capturing results with varying phrasings.
- Example: “Software Engineer NYC”
- Multi-Query Parallel Execution:
- Methodology: Execute multiple query variations simultaneously.
- Rationale: Enhances coverage by surfacing results through diverse linguistic patterns.
- Example query set:
- “Software Engineer NYC”
- “Java Developer New York”
- “Backend Engineer New York City”
- Temporal Filtering Mechanisms
- Methodology: Implement filters that prioritize recent results.
- Implementation examples:
- Google search operators: past week, past month (via APIs or UI filters).
- Bing API / SerpAPI: freshness=Month parameter.
- Framework-specific implementations (LangChain, internal search rerankers): –QDF=3 parameter, boosting documents updated within the past ~3 months.
Direct Google UI Simulation vs Custom Search API Integration
Agents have two primary architectural approaches once they determine that web search functionality is required.
Google UI Simulation (rarely implemented)
- Utilizes headless browser automation frameworks (Playwright, Puppeteer, Selenium) to load google.com and simulate user input.
- Inherently fragile and performance-intensive; UI modifications or CAPTCHA challenges frequently disrupt automation workflows.
- Elevated risk of violating Google’s Terms of Service.
Google Custom Search JSON API Integration (preferred methodology)
- Executes HTTPS requests containing query parameters, filters, and result count specifications.
- Receives structured JSON payloads containing titles, snippets, URLs, and metadata.
- Requires API key authentication and a programmable Custom Search Engine configuration, but provides stability and efficient caching capabilities.
Comparative Analysis
- UI simulation: ✅ Direct UI feature parity; ❌ Brittle architecture, performance overhead, and compliance risks.
- Custom Search API: ✅ Reliable, structured, automatable; ❌ Quota limitations and cost scaling at enterprise levels.
For more information: https://developers.google.com/custom-search/v1/overview
End-to-End Agent Workflow Architectures
Deterministic Workflow (LLM-Free Implementation)
- Objective
Construct optimized search queries from predefined templates and synonym dictionaries, then execute search API calls. Zero LLM token consumption.
Query Construction (Template-Based + Advanced Operators)
- Data Normalization:
- role: java software engineer → preserve exact match, augment with synonyms: backend engineer, software developer (java)
- location: NYC → expand to: New York City, “New York, NY”, Manhattan, Brooklyn
- temporal scope: last 7–30 days
- Construct multi-query set (precision + recall optimization):
(Queries 6–10 target ATS (Applicant Tracking System) pages to minimize aggregator noise.)1) "Java Software Engineer" "New York, NY" site:linkedin.com/jobs 2) ("Java" AND ("Software Engineer" OR "Backend Engineer")) "New York City" site:indeed.com 3) "Java developer" (NYC OR "New York, NY") site:glassdoor.com 4) intitle:(Java "Software Engineer") (NYC OR "New York, NY") (2025..2025) 5) "Java Software Engineer" "New York" filetype:html -intern -senior -staff 6) site:greenhouse.io "Java" ("New York" OR NYC) 7) site:lever.co "Java" ("New York" OR NYC) 8) site:boards.greenhouse.io "Java" "New York" 9) "Java" "Software Engineer" site:careers.google.com "New York" 10) "Java" "Software Engineer" site:jobs.netflix.com "New York"
- Data Normalization:
Processing Heuristics
- Temporal Filtering: prioritize pages updated within the last 14 days (API recency filter).
- Deduplication: canonicalize URLs, remove tracking parameters.
- Title Filtering: implement allowlist (
java,software engineer,backend), blocklist (senior,staff,principal,intern), unless user specifies otherwise. - Geographic Filtering: mandate NYC string matching; implement soft-matching for “hybrid New York”.
Example API Call (Bing Web Search / Google CSE / SerpAPI)
GET /search?q="Java+Software+Engineer"+"New+York,+NY"+site%3Alinkedin.com%2Fjobs&freshness=Month&count=20
Authorization: Bearer <API_KEY>
Post-Processing Pipeline (LLM-Free)
- Parse snippets for key indicators:
Java,Spring,NY,Hybrid,Visa. - Extract structured data using regex patterns:
title,company,location,posted_date,apply_url.
- Ranking Algorithm:
- Title matching score
- Company reputation (simple list or Crunchbase size classification)
- Temporal freshness
- Source priority: on-site/ATS > aggregator
- Output structured JSON or tabular format.
- Parse snippets for key indicators:
Deterministic Implementation Pseudocode (LLM-Free)
role = "java software engineer"
location_terms = ["NYC", "\"New York, NY\"", "\"New York City\"", "Manhattan", "Brooklyn"]
sites = [
"linkedin.com/jobs", "indeed.com", "glassdoor.com",
"greenhouse.io", "lever.co", "boards.greenhouse.io"
]
neg = ["-senior", "-staff", "-principal", "-lead", "-intern"]
base = f"({role}) ({' OR '.join(location_terms)}) {' '.join(neg)}"
queries = [f"site:{s} {base}" for s in sites] + [
f"intitle:(Java \"Software Engineer\") ({' OR '.join(location_terms)}) {' '.join(neg)}",
f"\"Java developer\" ({' OR '.join(location_terms)}) {' '.join(neg)}"
]
results = []
for q in queries:
results += search_api(q, freshness="Month", count=20)
rows = []
for r in dedupe(results):
if not title_ok(r.title):
continue
row = extract_with_regex(r)
rows.append(row)
final = rank(rows, keys=["title_match","freshness","ats_priority","company_size"])
return final[:30]
Use Cases: Typically employed when
- Speed, cost efficiency, and predictable behavior are prioritized for common query patterns.
Advantages/Disadvantages
- ✅ Cost-effective, high performance, predictable, cacheable.
- ❌ Inflexible: limited capability for fuzzy phrase matching, deduplication across noisy sites, and nuanced requirement summarization.
LLM-Orchestrated Workflow Architecture
- Objective
Enable the LLM to determine search strategies, refinement approaches, and summarization methodologies.
- ReAct-Style Implementation Flow
- Intent Recognition + Slot Filling (LLM)
- Extract structured data: role=Java Software Engineer, location=NYC, seniority=mid, must-haves=Java/Spring, preferences=hybrid/NYC.
- Query Planning (LLM)
- Generate diverse query strategies (precision + recall + vertical targeting):
- site:linkedin.com/jobs “Java Software Engineer” “New York, NY”
- site:greenhouse.io (Java AND “Software Engineer”) (“New York” OR NYC)
- (“Java developer” OR “Backend Engineer”) “New York” site:lever.co
- Implement temporal filtering (e.g., “past month”) if API supports it.
- Generate diverse query strategies (precision + recall + vertical targeting):
- Tool Execution (Non-LLM)
- Execute Search API calls with LLM-generated queries (zero token consumption).
- Content Extraction (Optional)
- If permitted, fetch job detail pages using:
- Lightweight HTML extractors for title/company/location/posted/description.
- Or process snippets/HTML chunks through LLM for information extraction when data is unstructured.
- If permitted, fetch job detail pages using:
- Refinement Loop (LLM)
- LLM identifies noisy/irrelevant results (e.g., “Senior/Staff”), proposes query modifications or implements blocklist (
-senior -staff -principal -lead -intern). - LLM may expand with semantic synonyms:
backend engineer,platform engineer (Java).
- LLM identifies noisy/irrelevant results (e.g., “Senior/Staff”), proposes query modifications or implements blocklist (
- Summarization + Ranking (LLM)
- Rank by user intent alignment and summarize each role (requirements, visa indicators if present, remote/hybrid specifications).
- Generate clean, deduplicated shortlist with reasoning.
- Intent Recognition + Slot Filling (LLM)
- Example LLM-Generated Query Set
A) "Java Software Engineer" "New York, NY" site:linkedin.com/jobs -senior -staff -principal -lead -intern
B) (Java AND ("Software Engineer" OR "Backend")) ("New York" OR NYC) site:lever.co
C) (Java AND Spring) ("New York" OR "NYC") site:greenhouse.io
D) intitle:(Java "Software Engineer") ("New York" OR NYC) -contract -intern
E) "Java developer" "New York" site:indeed.com date_posted:7d
Example Prompt Fragments (High-Level, Non-Chain-of-Thought)
- “Extract job title, company, location, posted date, and required skills from this HTML. If seniority level includes ‘senior’, mark as exclude_reason.”
- “Given the user wants NYC roles, rank by location proximity (NYC > Hybrid NYC > NY state > Remote US).”
LLM-Agent Implementation Pseudocode (With Tools)
user_input = "I would like to know if there are any current openings for a Java Software Engineer in NYC"
plan = LLM("""
You are a job search agent. Extract role, location, seniority, must-have tech.
Return JSON with fields.
""", user_input)
queries = LLM("""
Generate 6 web search queries targeting ATS and job boards.
Prefer site:greenhouse.io, site:lever.co, site:linkedin.com/jobs.
Exclude senior/staff/lead/intern.
Include NYC variants and freshness.
""", plan)
raw = []
for q in queries:
raw += search_api(q, freshness="Month", count=20)
# Optional page fetch for details
pages = fetch_pages([r.url for r in top_k(raw, 40)])
structured = LLM("""
From each page snippet/HTML, extract:
title, company, location, posted_date, apply_url, seniority_label, skills.
Exclude if seniority >= Senior. Return JSON list.
""", pages)
ranked = LLM("""
Rank the roles for a mid-level Java SE in NYC.
Bucket by: Onsite NYC, Hybrid NYC, Remote US.
""", structured)
return ranked
Use Cases: Typically employed when
- Input is ambiguous (“backend role near NYC, willing to commute”).
- Robust field extraction from unstructured pages is required.
- High-quality summaries or nuanced preference-based reranking is desired.
Advantages/Disadvantages
- ✅ Flexible: enhanced recall, intelligent deduplication, superior summaries, adaptive to ambiguous inputs.
- ❌ Token costs; requires guardrails to prevent hallucinations; demands careful prompt/tool design and caching strategies to control latency/cost.
Free vs Paid Agent Capability Tiers
Free Tier Capabilities
- Cost-Optimized, Deterministic Search Architecture
- Typically implements LLM-free pathways:
- Predefined query templates (e.g., “Java Software Engineer” “New York”).
- Single search API execution (Bing, SerpAPI, DuckDuckGo, etc.).
- Minimal post-processing (regex or basic keyword matching).
- Rationale:
- Cost minimization (zero token consumption).
- Performance optimization (no multi-step reasoning).
- Scalability for large free-tier user bases.
- Typically implements LLM-free pathways:
- Minimal LLM Integration (if implemented):
- Limited to final summarization of snippets in natural language.
- Excludes query planning or iterative refinement processes.
Paid Tier Capabilities
- LLM-Integrated Search Architecture
- Paid users typically receive comprehensive agent workflows:
- LLM interprets user intent, rewrites and expands queries.
- LLM determines target sites and filters irrelevant results.
- LLM extracts structured information from unstructured HTML snippets.
- LLM performs ranking and summarization, delivering a “research assistant” experience.
- Paid users typically receive comprehensive agent workflows:
- Implementation Rationale:
- Higher token consumption → increased costs, reserved for paying customers.
- Enhanced UX → premium differentiation (summaries, reasoning, deduplication).
- Supports ambiguous/natural queries beyond free-tier template capabilities.
Model Selection Impact
Model choice is critical: - Smaller/cost-effective models (free tier) → typically rule-based search + minimal LLM summarization. - Advanced models (GPT-4, Claude Opus, Gemini Ultra, etc.) (often premium) → enable query planning, multi-step refinement, complex summarization. Architecture Summary:
- Free tier = template-driven search + optional lightweight LLM summarization.
- Paid tier = comprehensive LLM-driven agent workflows (reasoning, multiple queries, summarization, deduplication).
- Business Strategy = provider-dependent: some maintain lightweight search even in paid tiers, while others unlock “research-grade” workflows behind premium paywalls.
Architecture Summary
Free tiers typically implement deterministic search with minimal LLM integration (for cost optimization). Paid tiers generally provide LLM-integrated agents that deliver enhanced flexibility, superior search quality, and advanced summarization capabilities. The specific implementation depends on the provider’s architectural design and the model capabilities they’re willing to invest in.
References
- A Survey of Large Language Model Empowered Agents for Search & Recommendation Systems (arXiv)
- LLM-Agent-for-Recommendation-and-Search
- Towards AI Search Paradigm (arXiv)
- AI Agents 101: Everything You Need to Know About Agents (Medium)
- LLM Agents (PromptingGuide.ai)
- Evaluating Web Search Agent with LLM (Mirascope Docs)
- Mastering AI Agents: Components, Frameworks, and RAG (TowardsAI)
- New tools for building agents: Responses API, web search … (OpenAI)
- Google Search Operators (Google Support)