Overview
In a distributed microservice environment, load balancing is critical for achieving scalability, fault tolerance, and efficient traffic routing. Understanding where the balancing occurs—on the client side or the server side—helps architects design systems that are both resilient and cost-efficient.
In this blog, I will share two important concepts that define how traffic distribution is managed in a microservices ecosystem: Client-Side Load Balancing and Server-Side Load Balancing.
Key Concepts Covered in this Blog
- Client-Side Load Balancing
- Server-Side Load Balancing
- When to Use Each Approach
- Best Practices and Critical Use Cases
- References
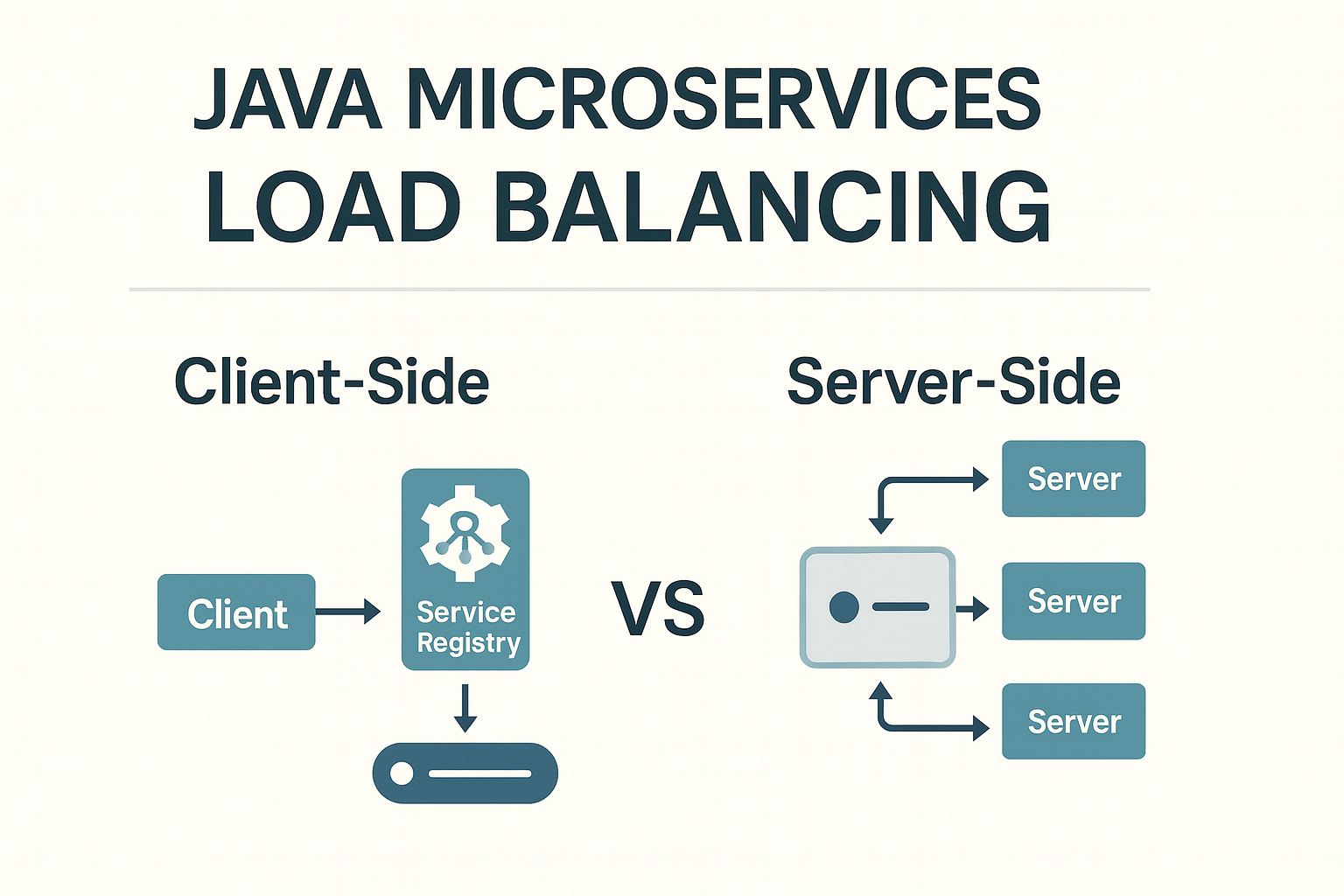
Client-side Load Balancing VS Server-Side Load Balancing
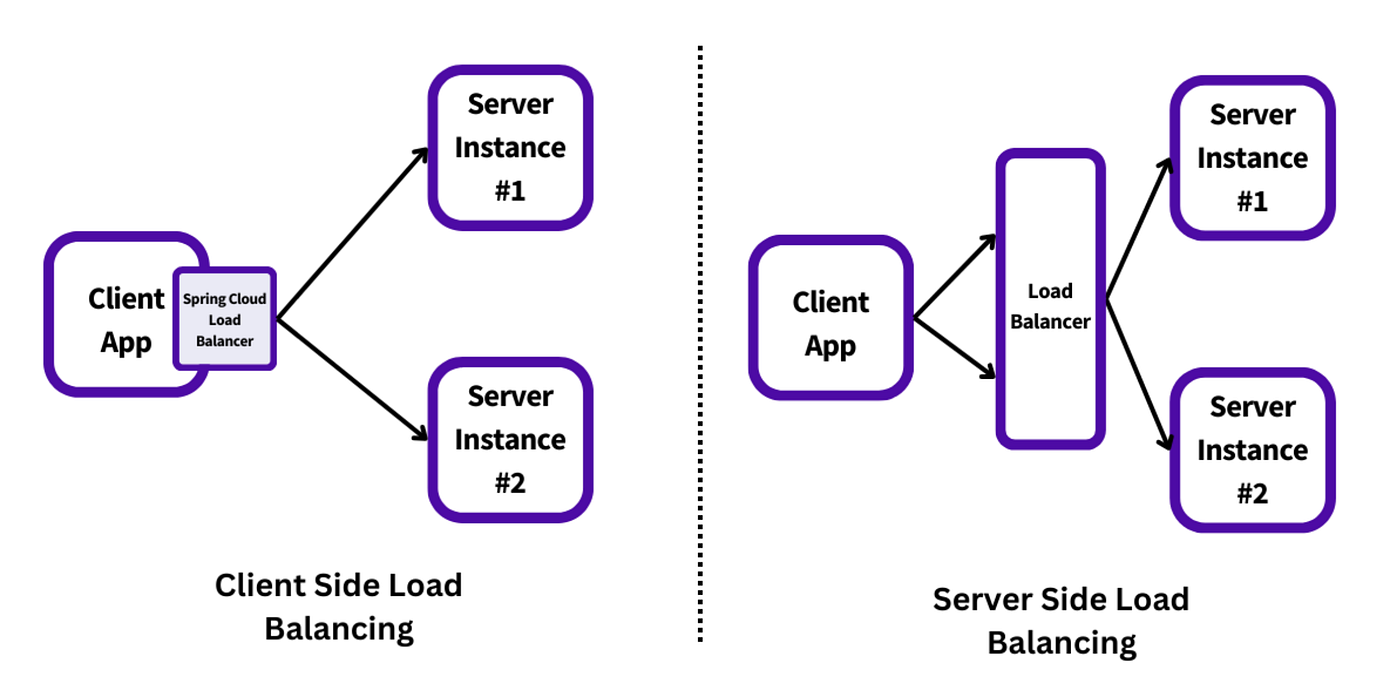
Client-Side Load Balancing
Example: Spring Cloud LoadBalancer
How It Works:
- The client queries the Service Registry (e.g., Eureka, Consul) for available service instances.
- The registry returns a list of healthy endpoints (IP + port).
- The client applies a load balancing strategy (Round Robin, Random, Weighted, etc.) to pick one instance.
- The client then calls the selected instance directly.
When to Use (Critical Use Cases):
- ✅ You have a Service Discovery mechanism (e.g., Eureka, Consul, Zookeeper).
- ✅ The system does not rely on an external load balancer.
- ✅ You want fine-grained, application-level control over routing logic.
- ✅ Internal microservice-to-microservice communication within a closed network.
Why It Matters:
Client-side balancing reduces external dependency, minimizes latency, and gives developers flexibility in implementing custom routing or retry policies.
Server-Side Load Balancing
Example: AWS Application Load Balancer (ALB), NGINX, HAProxy
How It Works:
- The load balancer acts as a single entry point for incoming traffic.
- It maintains a list of backend targets and performs health checks to ensure availability.
- Incoming requests are distributed automatically to healthy instances using balancing algorithms.
- The client interacts only with the load balancer, not individual services.
When to Use (Critical Use Cases):
- ✅ Public-facing APIs or external traffic entering the system.
- ✅ Environments requiring centralized routing, SSL termination, or WAF integration.
- ✅ Applications deployed across multiple zones or regions for high availability.
- ✅ Scenarios where you want infrastructure-managed scaling and health monitoring.
Why It Matters:
Server-side balancing offloads complexity from the client, improves observability and security, and integrates well with cloud-native scaling and fault recovery mechanisms.
Summary
- Use Client-Side Load Balancing for internal microservice communication where you control discovery and routing logic.
- Use Server-Side Load Balancing for external or cross-boundary traffic, where centralized routing, fault isolation, and scalability are critical.